

In today’s post I will be walking you through a Python Library called LangDetect that will do the job of Text Language Detection for you.
The Library we will be using is called LangDetect
It is a Language-detection library ported from Google’s language-detection of Nakatani Shuyo’s language-detection library.
Below are some coverage about this library/method.
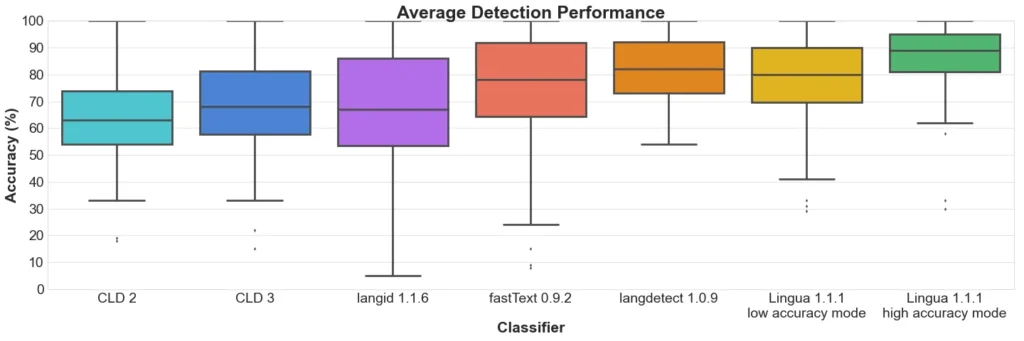
Image credits to Reddit.
Someone on Reddit posted this benchmarking in terms of the accuracy of detecting the language in question.
From the looks of it, LangDetect appears to be in a very good positioning with it being stacked at 4th position accuracy-wise in terms of the median.
Side note: No library can come close to promising 100% accuracy, but based on my experience with this library it was very close to predicting certain languages with a higher accuracy.
Without further ado, I am sharing the script below which you can use in Google Colab
Step 1: Installations
!pip install pandas langdetect
Step 2: Imports & Uploading Your CSV
import pandas as pd
from langdetect import detect
from google.colab import files
# Upload the CSV file
uploaded = files.upload()
# Get the filename of the uploaded file
input_filename = list(uploaded.keys())[0]
# Read the CSV file
df = pd.read_csv(input_filename)
print(df.head())
Step 3: Function to Detect & Classify Languages
def detect_language(text):
try:
return detect(text)
except:
return 'unknown'
Step 4: Dataframe Preview & Generating Output CSV
# Apply language detection to the 'title' column
df['detected_language'] = df['title'].apply(detect_language)
# Display the first few rows of the result
print(df.head())
# Save the result to a new CSV file
output_filename = 'output_with_language.csv'
df.to_csv(output_filename, index=False)
# Download the output file
files.download(output_filename)
Probable Use Cases
- You have an English domain with foreign language titles, you can classify non-English & plan their pruning
- Ensuring that the correct language content is sitting on the international site.
Fun fact: I was able to classify about 100k titles within 10-20 minutes.
In my case, I had uploaded a CSV with the mapping of URL to Title column which is why you will find code function in this manner, but you can rework the script for your specific use case.

Kunjal Chawhan founder of Decode Digital Market, a Digital Marketer by profession, and a Digital Marketing Niche Blogger by passion, here to share my knowledge